Since Metadata Injection (MDI) with Pentaho Data Integration gets more and more popular and used in a lot of projects, this blog post provides examples that help in special scenarios.
It is a follow up from my previous blog post about Metadata Injection that provide you with some more basics and background. The feature has also been improved in PDI 7.0 and we continue to do so in future releases. For more details, have a look at the Pentaho Documentation about Metadata Injection.
All the following examples can be downloaded here: MDI_Examples.zip
Special Example: MDI with the Filter Rows step
The Filter Rows step is a special MDI scenario, since it has a nested structure of filter conditions (this applies accordingly to Join Rows step).
Example: a OR b
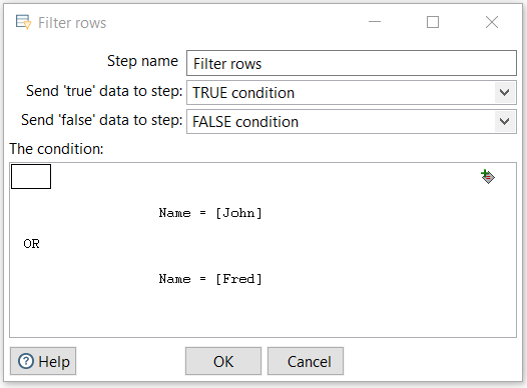
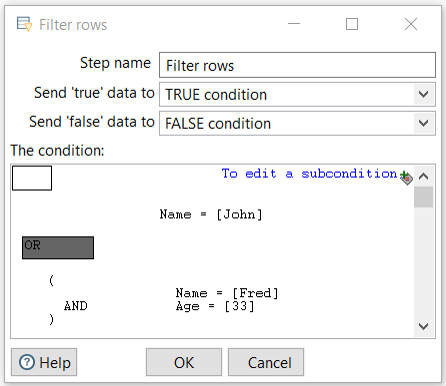
Example: a OR (x AND y)
The MDI condition is given in XML notation, for example:
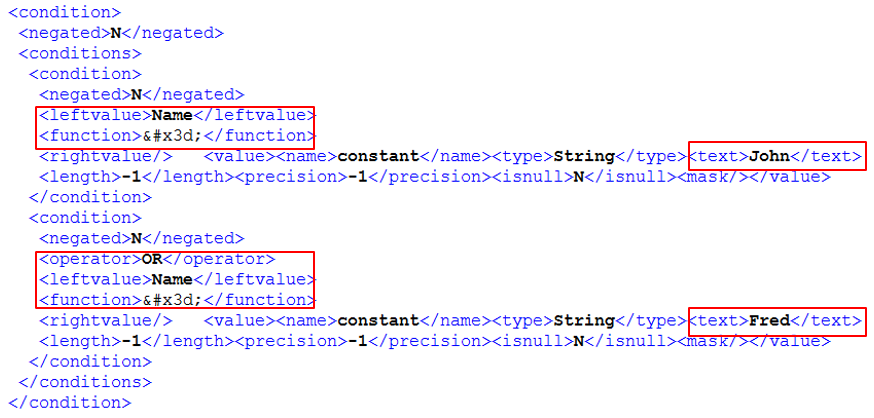
The condition XML has the same format as we store the transformation meta data in a KTR file in XML format. We do not have a DTD (Document Type Definition) for the KTR XML format, nor the condition. But it is very easy to get to a XML condition:
- Create a sample Filter step with the different conditions you need. This gives you all the information, for example the value for function (in our example = represents the equal function)
- Select the step and Copy it to the clipboard. Paste it into a text editor. Alternatively you can store the KTR and open the KTR in a text editor.
- Find the <condition> element and their nested elements and modify it accordingly to use it in your MDI scenario.
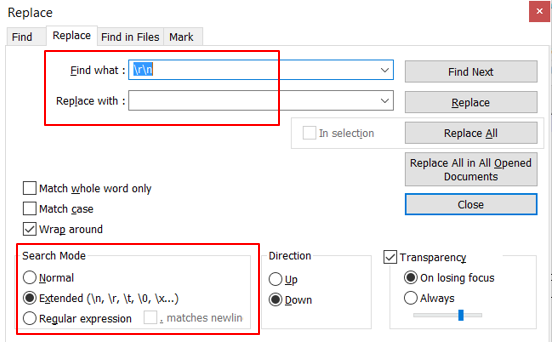
Hint to remove the CR and LF within the XML in case you need a single line:
- Use Notepad++ or a similar text editor
- Replace \r\n and leave the „Replace with“ field empty
- Make sure to switch to Extended Search Mode
Different MDI Architectures
In general, a MDI process can:
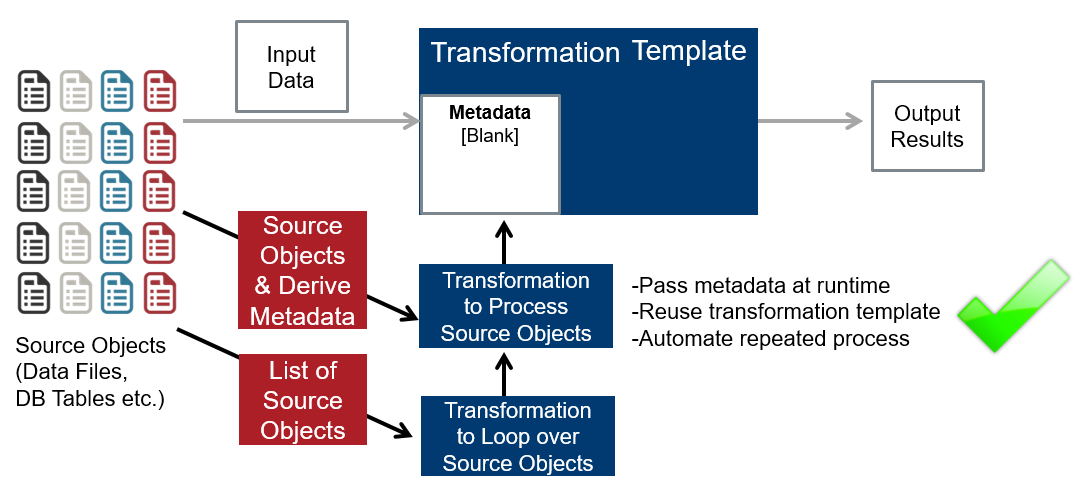
- „Just“ inject metadata and call the template transformation –> we call this the MDI Standard use case
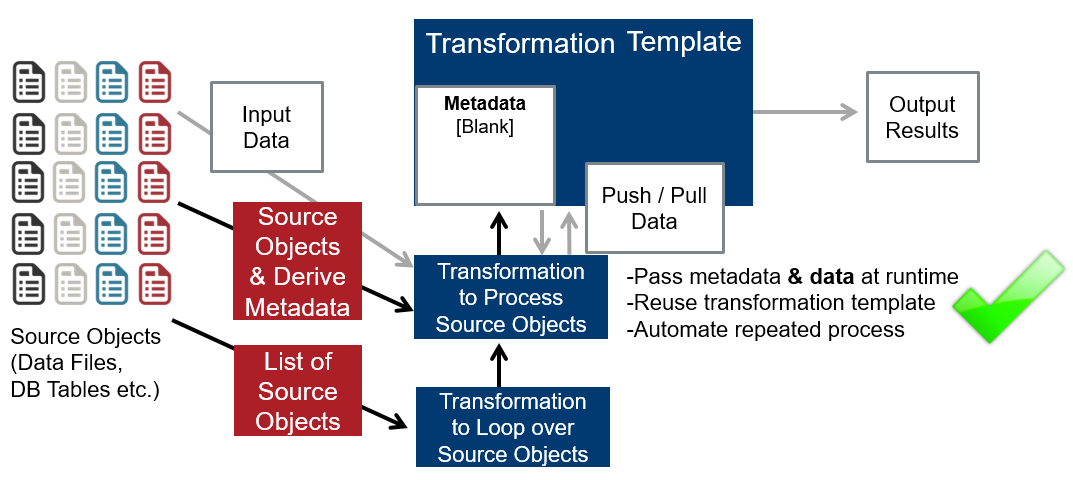
- Additionally, the data can get pushed (streamed) from the main to the template transformation and also pulled back. This is needed when the template processes dynamic data from the main transformation. –> we call this the MDI Data Flow use case
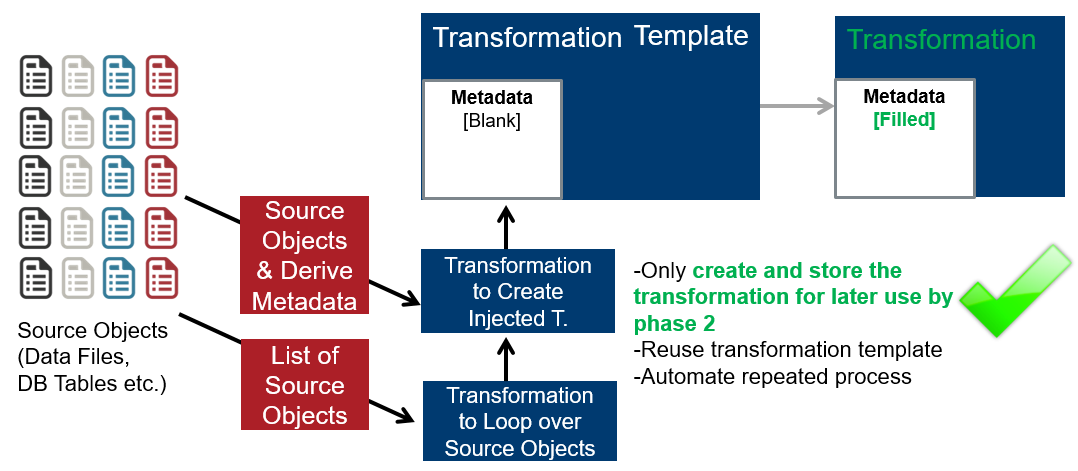
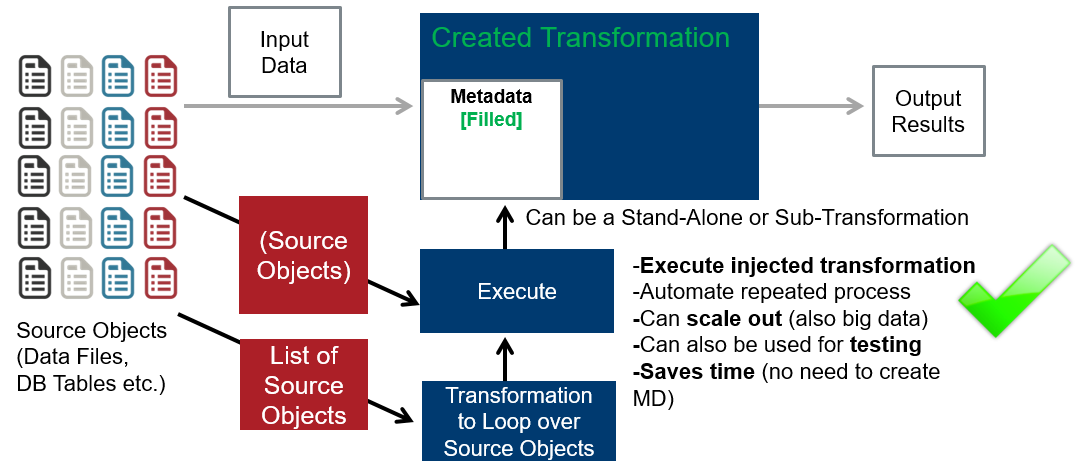
- For big data use cases, we can fill the template transformation with metadata and store it (phase 1). Then this stored transformation can be copied and executed on multiple nodes (phase 2).–> we call this the MDI 2 Phase Processing use case, also used in our Onboarding Blueprint for Big Data: Filling the Data Lake
The following graphics illustrate these different architectures.
Scenario & Architecture for Standard:
Scenario & Architecture for Data Flow:
Scenario & Architecture for 2 Phase Processing – Phase 1:
Scenario & Architecture for 2 Phase Processing – Phase 2:
All the examples can be downloaded here: MDI_Examples.zip

And last but not least: If you miss a feature, let us know in JIRA (when you are a community user) or contact Pentaho Customer Support (when you are a Pentaho customer) to let us know about your feature requests and use cases. The more we know what is needed, the more we can help. Join us, either as a customer or community member, to leverage the power of Pentaho.