As I mentioned yesterday, Metadata Injection is my favorite part of this release. Now I get to explain why.
Metadata Injection (MDI) gives you the ability to modify transformations at execution time.
By dynamically passing source metadata to PDI at run time, IT teams can drive hundreds of data ingestion and preparation processes through just a few actual transformations. This promotes reusability and productivity, accelerating the creation of complex data onboarding processes.
How does Pentaho 6.1 and data onboarding relate back to the analytic data pipeline?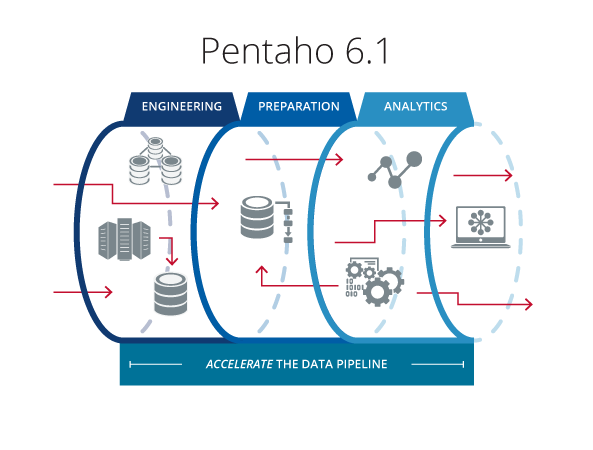 Organizations face challenges scaling their data pipelines to accommodate exploding data variety, volume, and complexity. In particular, it can take considerable time and resources to engineer and prepare data for the following types of enterprise use cases:
Organizations face challenges scaling their data pipelines to accommodate exploding data variety, volume, and complexity. In particular, it can take considerable time and resources to engineer and prepare data for the following types of enterprise use cases:
- Migrating hundreds of tables between databases
- Ingesting hundreds of changing data sources into Hadoop
- Enabling business users to onboard a variety of data themselves
The modern data onboarding necessary in these projects is more than just ‘connecting to’ or ‘loading’ data. Rather, it involves managing a scalable, repeatable process to ingest an array of changing data sources.
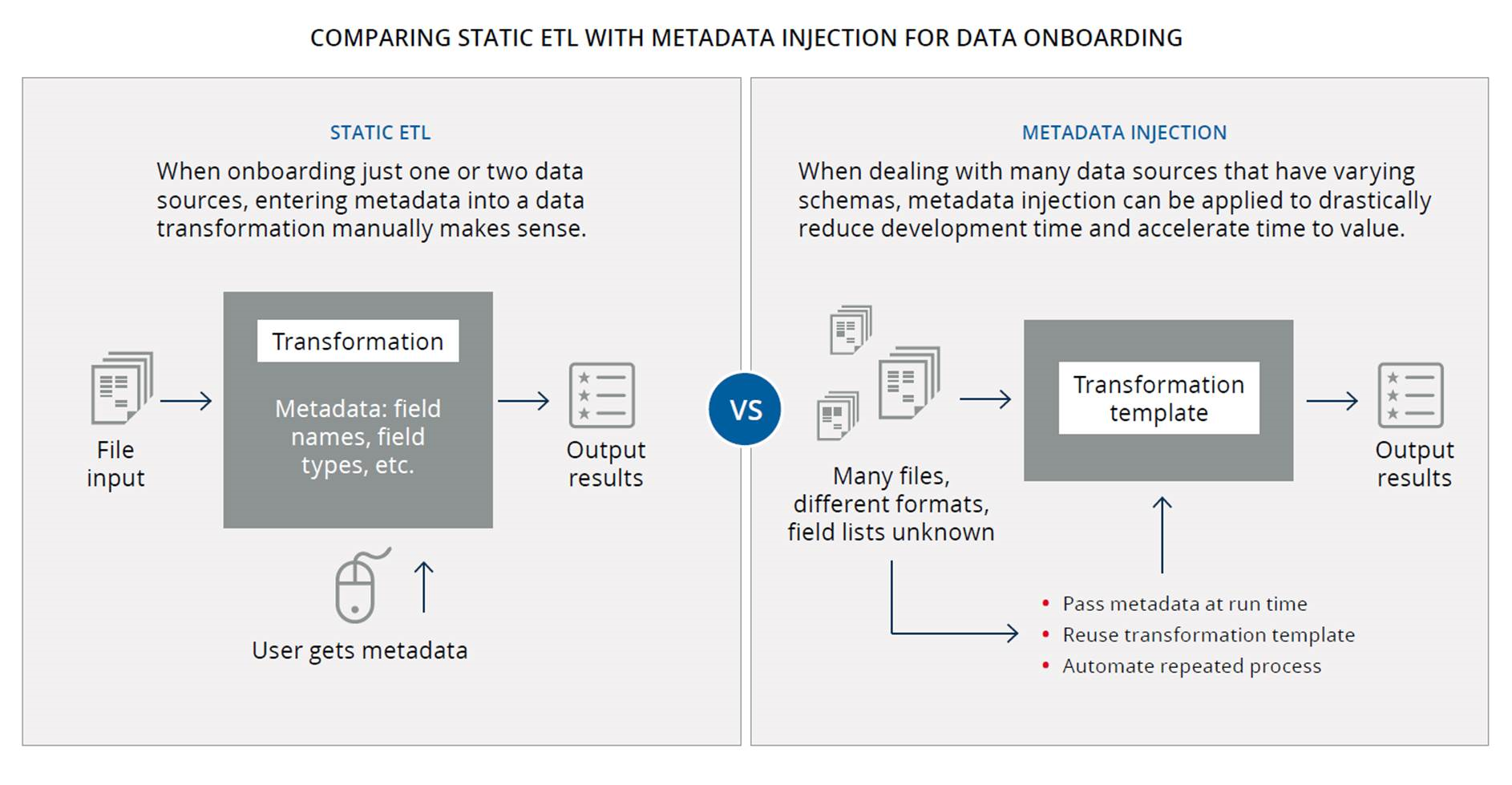
Traditional static ETL or hand-coding approaches require repetitive, time-consuming manual design that can increase the risk of human error. Meanwhile, this leads to staffing challenges and increased backlog. IT labor hours are tied up in risky, long term development projects when there are other potentially more valuable projects that could be worked on instead (opportunity cost).
What is metadata injection and why is it useful?
Recall that metadata is “a set of data that describes and gives information about other data.” In the context of a simple PDI transformation, examples of metadata include the field names, field types (string, number, etc), and field lengths (5 characters or 50?) from a CSV file input step in PDI. Normally, this metadata is accessed manually when a user creates the transformation, such as by hitting the Get Fields button in the CSV input step.
Metadata injection refers to the dynamic passing of metadata to PDI transformations at run time in order to control complex data integration logic. The metadata (from the data source, a user defined file, or an end user request) can be injected on the fly into a transformation template, providing the “instructions” to generate actual transformations. This enables teams to drive hundreds of data ingestion and preparation processes through just a few actual transformations, heavily accelerating time to data insights and monetization. In data onboarding use cases, metadata injection reduces development time and resources required, accelerating time to value. At the same time, the risk of human error is reduced.
BTW: If you are a fan of Data Vault Modeling, MDI can help here a lot as well.
Here is a comparison of static data integration with metadata injection:
How it all began: This feature exists since PDI 4.1 and Matt Casters blogged about this with a very nice example back in 2011: Parse nasty XLS with dynamic ETL
In Pentaho 6.1, we have hardened and enhanced our metadata injection capabilities. This includes enabling metadata injection with new steps, providing new documentation and examples on help.pentaho.com, and making other standardizations and improvements.
Here is a list of PDI steps that support metadata injection as of PDI 6.1:

Sample: We also added a tutorial for MDI with a step-by-step documentation to create a solution to parse different Excel files that contain invoice data from suppliers to process and unify:
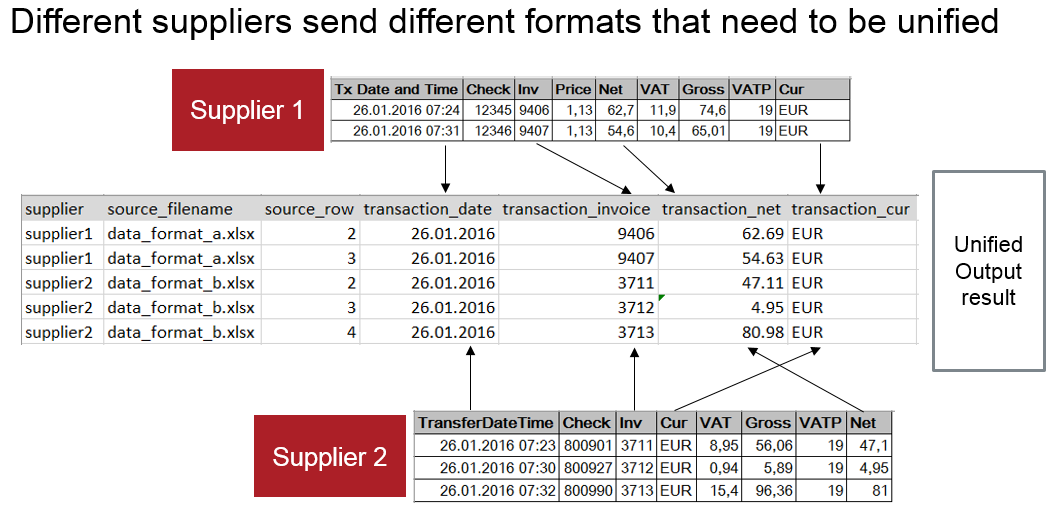
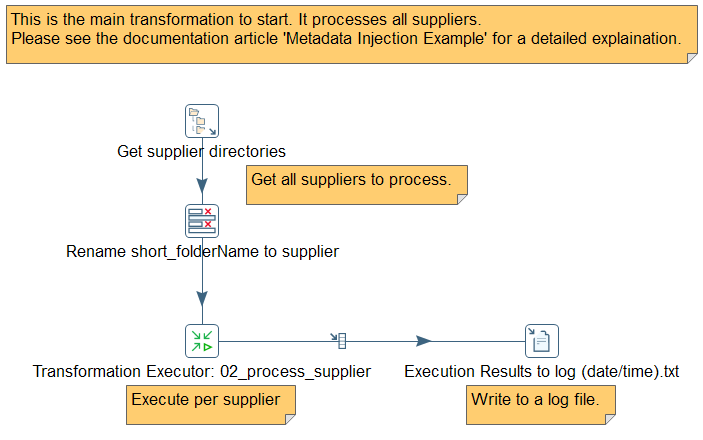
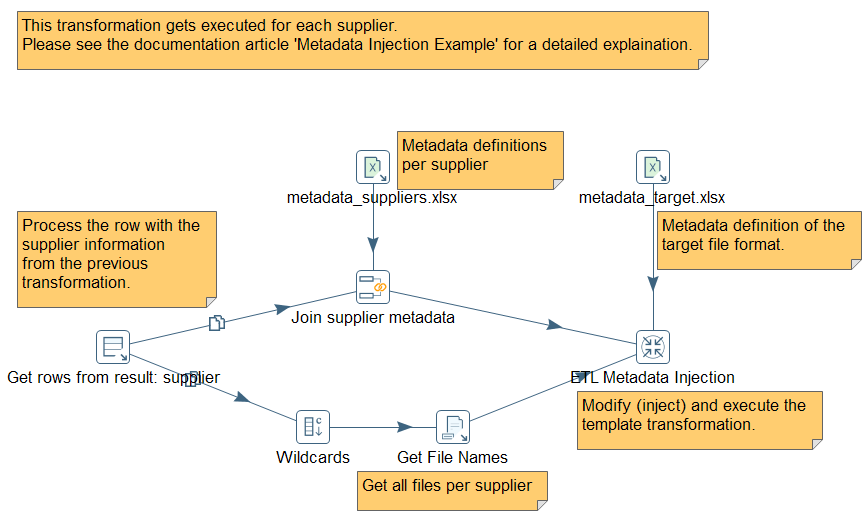
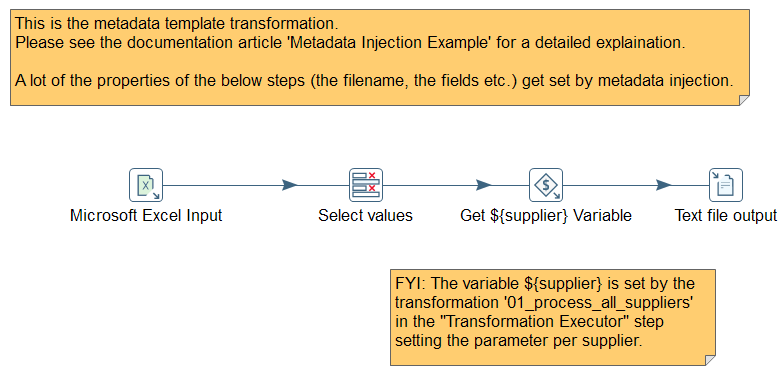
For more details, have a look at the Pentaho Documentation about Metadata Injection. You can download the complete sample here: flex_file_reader_metadata_injection.zip
This is a simplified example for illustration to store the data in a text file. It can even be used in all sorts of use cases and can store the data in SQL, NoSQL databases or Big Data. You have all the capabilities of PDI – sometimes I hear the term Swiss Army Knife 🙂
The journey continues and our engineering teams already work with full steam ahead to add more and more capabilities in the upcoming release – stay tuned!
And last but not least: If you miss a feature, let us know in JIRA (when you are a community user) or contact Pentaho Customer Support (when you are a Pentaho customer) to let us know about your feature requests and use cases. The more we know what is needed, the more we can help. Join us, either as a customer or community member, to leverage the power of Pentaho.
You can read the details with more information in our documentation What’s New in Pentaho 6.1.
Learn more about Pentaho 6.1 including a video overview, download link, webinar and more: Just follow this link.