This step provides the ability to read data from any type of XML file using the StAX parser. The existing Get Data from XML step is easier to use but uses DOM parsers that need in memory processing and even the purging of parts of the file is not sufficient when these parts are very big.
The XML Input Stream (StAX) step uses a completely different approach to solve use cases with very big and complex data stuctures and the need for very fast data loads: Since Kettle has so many own steps to process data in different ways, the processing logic has been moved more into the transformation and the step itself provides the raw XML data stream together with additional and helpful processing information.
Since the processing logic of some XML files can sometimes be very tricky, a good knowledge of the existing Kettle steps is recommended to use this step. Please see the different samples at the Kettle Wiki for illustrations of the usage.
Note: In almost all use cases, a Set/Reset functionality was needed. At this time it can be accomplished by the Modified Java Script Value step or the User Defined Java Class step where the latter one is recommended and much more faster. An own Kettle step with Set/Reset functionality is one the road map to solve these and other similar use cases, see PDI-6389 for more details.
Choose this step, whenever you have limitations with other steps or when you are in need of parsing XML with the following conditions:
- Very fast and independend of the memory regardless of the file size (GBs and more are possible due to the streaming approach)
- Very flexible reading different parts of the XML file in different ways (and avoid parsing the file many times)
Here is an example of parsing the following XML file with 2 main sample data blocks (Analyzer Lists & Products):
 Test 2 - XML")
A preview on the step may look like this (depending on the selected fields):
 Test 2 - Preview")
You see you really get almost the original streaming information with Elements and Attributes from the XML file together with helpful other fields like the element level.
Since the processing logic of some XML files can sometimes be very tricky, a good knowledge of the existing Kettle steps is recommended to use this step. Please see the different samples of this step for illustrations of the usage.
The transformation looks like this:
 Test 2 - Transformation")
The end result for the Analyzer List block:
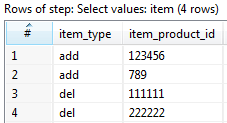
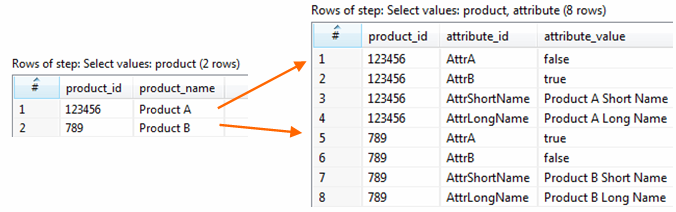
The end result for the Products block (splitted for example into two separate data streams for the end system):
And there are a lot more options in the step to help to solve your needs:
 Test 2 - Step Options")
More details about this step can be found in the XML Input Stream (StAX) documentation.
And for more details on the features for the upcoming PDI 4.2, please have a look at Matt’s blog.